


Редактор скриптов GTA4
Автор Capushon, 07 Apr 2009 22:17
Сообщений в теме: 89
#1

Capushon
-
- Пользователи
-

- 39 сообщений
Активный участник
- Пол:Мужчина
- Город:Украина
Отправлено 07 April 2009 - 22:17
Создаю тему, в которой, надеюсь, будет что обсуждать...
Начало положено
Сначала ты надежда и гордость,
Потом о спину ломают аршин. ©БГ
#2
Johnix
-

- Пользователи
-
- 87 сообщений
Активный участник
- Пол:Мужчина
- Город:Новосибирск
Отправлено 08 April 2009 - 15:14
что-то я не понял что за прога, типа санни билдер чтоле?


#3
listener
-

- Главные администраторы
-
- 356 сообщений
Активный участник
- Пол:Мужчина
- Город:Ft.Lauderdale
-
")
Отправлено 08 April 2009 - 16:27
Прога которой еще нет. (Но, которая нужна).что-то я не понял что за прога, типа санни билдер чтоле?
Приду с работы, попробую собрать в кучу заметки по этой теме и выложить предварительное описание языка для обсуждения.
You think your day was surreal? Try mine.
#4
listener
-
- Главные администраторы
-
- 356 сообщений
Активный участник
- Пол:Мужчина
- Город:Ft.Lauderdale
-
Отправлено 08 April 2009 - 21:52
Итак, для начала, несколько необходимых разъяснений.
Если под "скрипт билдером" понимается ide, с возможностью написания своих и редактирования имеющихся скриптов, интеграцией (и, возможно, редактированием игровых ресурсов (например, .gxt) и прочими интересными и полезными вещами) - то им пока никто не занимается. Моя текущая цель - написать простой комманд-лайновый компилятор (и декомпилятор). Остальным имеет смысл заниматься, после того, как эта цель будет достигнута.
Я собираюсь здесь собрать вместе заметки, которые у меня есть на эту тему. Возможно (если я его все-же допишу), из
этого получится описание языка. Плюс, есть вероятность, что я упустил что-то важное.
Начнем с того, что лично я не знаю, как выглядят исходники скриптов IV. Я не исключаю даже вероятность, что там используется слегка расширенный синтаксис .sc из GTA III. Чтобы, с одной стороны, не гадать, а как же оно было в оригинале, а, с другой, снизить вероятность ошибок в скриптах, я беру за основу синтаксис C99 с небольшими изменениями.
В дальнейшем, никто не мешает сделать альтернативные парсеры для любого другого синтаксиса. Парсер - примерно 20% от овсего компилятора, и, по готовым конструкциям, написать его будет несложно.
Архитектурные отличия нового скриптового интерпретатора - достаточно большие. Изменилась организация памяти, появились нормальные функции, появились структуры... перечислять можно долго, поэтому обо всем по порядку.
1. Архитектура виртуальной машины.
Скриптовая часть игры состоит из набора скриптов. Скрипты собираются в один img-архив.
Каждый скрипт исполняется в отдельном потоке.
Файл скрипта содержит два или три сегмента: сегмент кода (т.е. массив байт-кодов), сегмент статических данных (к которым имеет доступ только этот скрипт) и, опционально, сегмент глобальных даных (доступных из любого скрипта).
Сегмент глобальных данных содержится в одном (и только в одном) скрипте. Как правило, это startup.sco
У сегмента глобальных данных есть версия - некое 32-битное число. Любой скрипт содержит версию глобальных данных, с которой он работает. При несовпадении версии, скрипт не загружается. (В текущей версии игры, если в этом поле заголовка казан 0, проверка не производится. Зачем это сделано, я не знаю). Попытка загрузить еще один скрипт, содержащий глобальный сегмент, также приводит к ошибке.
Интерпретатор скрипта, представляет собой стековую виртуальную машину (т.е., все промежуточные данные хранятся на стеке).
Каждая функция имеет стековый фрейм, в котором хранятся локальные переменные этой функции.
В отличие от предыдущих GTA, используется минимальное количество байткодов (75 для консольных версий и 78 для PC, из них три команды - не используются). Это позволило уменьшить размер самого интерпретатора с ~500К (GTA SA) до ~8К. Все взимодействие с игровым кодом производится через native функции - специальным образом зарегистрированные функции .exe
Каждый скрипт содержит все свои используемые функции - вызов функций из другого скрипта невозможен.
Это сняло ограничения на использование статических переменных (локальных переменных потока, в котором исполняется этот скрипт), но привело в ощутимому раздуванию общего размера скриптов.
2. Используемые типы данных.
скрипты используют четыре простых типа данных:
* int - целое, со знаком, 4 байта
* float - число с плавающей точкой, 4 байта
* vector - структура из трех float, 12 байт
* string - строка, как правило, 8 бит на символ. В коде может представляться как в виде указателя (4 байта), там и в виде массива байтов, используемого как буфер. Размер буфера округляется вверх, до кратного четырем.
поддерживаются два основных типа: массив и структура.
Массив - набор неименованных переменных одного типа (в т.ч., это могут быть другие массивы и структуры), структура - набор именованных полей произвольного типа.
кроме этого, есть ссылки на переменные (передача значения в функцию по указателю). От "нормальных" указателей, ссылки отличаются тем, что мадификация ссылок и адресная арифметика не поддерживаются на уровне VM.
Типизация достаточно строгая. Возможны некоторые трюки, с целью обхода проверки типов, непосредственно на уровне байткода, но, на высоком уровне это не поддерживается (и поддерживаться не должно). Проверка на выход за пределы массива, например, осуществляется в самой VM.
Поскольку у нас есть строгая типизация, я планирую ввести несколько производных типов на уровне языка, дабы избежать лишних ошибок. В первую очередь, к ним относятся типы данных, получаемых извне, из которых внитри скрипта получить ничего не возможно.
(PEDHANDLE, VEHHANDLE, OBJHANDLE и прочие хэндлы, которые не получится ни модифицировать, ни присвоить какому-то другому типу). Возможно, будет bool. Точно будет запись хэшей в виде $string и ${string with spaces}.
Продолжение следует, вопросы и предложения приветствуются...
Если под "скрипт билдером" понимается ide, с возможностью написания своих и редактирования имеющихся скриптов, интеграцией (и, возможно, редактированием игровых ресурсов (например, .gxt) и прочими интересными и полезными вещами) - то им пока никто не занимается. Моя текущая цель - написать простой комманд-лайновый компилятор (и декомпилятор). Остальным имеет смысл заниматься, после того, как эта цель будет достигнута.
Я собираюсь здесь собрать вместе заметки, которые у меня есть на эту тему. Возможно (если я его все-же допишу), из
этого получится описание языка. Плюс, есть вероятность, что я упустил что-то важное.
Начнем с того, что лично я не знаю, как выглядят исходники скриптов IV. Я не исключаю даже вероятность, что там используется слегка расширенный синтаксис .sc из GTA III. Чтобы, с одной стороны, не гадать, а как же оно было в оригинале, а, с другой, снизить вероятность ошибок в скриптах, я беру за основу синтаксис C99 с небольшими изменениями.
В дальнейшем, никто не мешает сделать альтернативные парсеры для любого другого синтаксиса. Парсер - примерно 20% от овсего компилятора, и, по готовым конструкциям, написать его будет несложно.
Архитектурные отличия нового скриптового интерпретатора - достаточно большие. Изменилась организация памяти, появились нормальные функции, появились структуры... перечислять можно долго, поэтому обо всем по порядку.
1. Архитектура виртуальной машины.
Скриптовая часть игры состоит из набора скриптов. Скрипты собираются в один img-архив.
Каждый скрипт исполняется в отдельном потоке.
Файл скрипта содержит два или три сегмента: сегмент кода (т.е. массив байт-кодов), сегмент статических данных (к которым имеет доступ только этот скрипт) и, опционально, сегмент глобальных даных (доступных из любого скрипта).
Сегмент глобальных данных содержится в одном (и только в одном) скрипте. Как правило, это startup.sco
У сегмента глобальных данных есть версия - некое 32-битное число. Любой скрипт содержит версию глобальных данных, с которой он работает. При несовпадении версии, скрипт не загружается. (В текущей версии игры, если в этом поле заголовка казан 0, проверка не производится. Зачем это сделано, я не знаю). Попытка загрузить еще один скрипт, содержащий глобальный сегмент, также приводит к ошибке.
Интерпретатор скрипта, представляет собой стековую виртуальную машину (т.е., все промежуточные данные хранятся на стеке).
Каждая функция имеет стековый фрейм, в котором хранятся локальные переменные этой функции.
В отличие от предыдущих GTA, используется минимальное количество байткодов (75 для консольных версий и 78 для PC, из них три команды - не используются). Это позволило уменьшить размер самого интерпретатора с ~500К (GTA SA) до ~8К. Все взимодействие с игровым кодом производится через native функции - специальным образом зарегистрированные функции .exe
Каждый скрипт содержит все свои используемые функции - вызов функций из другого скрипта невозможен.
Это сняло ограничения на использование статических переменных (локальных переменных потока, в котором исполняется этот скрипт), но привело в ощутимому раздуванию общего размера скриптов.
2. Используемые типы данных.
скрипты используют четыре простых типа данных:
* int - целое, со знаком, 4 байта
* float - число с плавающей точкой, 4 байта
* vector - структура из трех float, 12 байт
* string - строка, как правило, 8 бит на символ. В коде может представляться как в виде указателя (4 байта), там и в виде массива байтов, используемого как буфер. Размер буфера округляется вверх, до кратного четырем.
поддерживаются два основных типа: массив и структура.
Массив - набор неименованных переменных одного типа (в т.ч., это могут быть другие массивы и структуры), структура - набор именованных полей произвольного типа.
кроме этого, есть ссылки на переменные (передача значения в функцию по указателю). От "нормальных" указателей, ссылки отличаются тем, что мадификация ссылок и адресная арифметика не поддерживаются на уровне VM.
Типизация достаточно строгая. Возможны некоторые трюки, с целью обхода проверки типов, непосредственно на уровне байткода, но, на высоком уровне это не поддерживается (и поддерживаться не должно). Проверка на выход за пределы массива, например, осуществляется в самой VM.
Поскольку у нас есть строгая типизация, я планирую ввести несколько производных типов на уровне языка, дабы избежать лишних ошибок. В первую очередь, к ним относятся типы данных, получаемых извне, из которых внитри скрипта получить ничего не возможно.
(PEDHANDLE, VEHHANDLE, OBJHANDLE и прочие хэндлы, которые не получится ни модифицировать, ни присвоить какому-то другому типу). Возможно, будет bool. Точно будет запись хэшей в виде $string и ${string with spaces}.
Продолжение следует, вопросы и предложения приветствуются...
You think your day was surreal? Try mine.
#5
Capushon
-
- Пользователи
-
- 39 сообщений
Активный участник
- Пол:Мужчина
- Город:Украина
Отправлено 13 April 2009 - 15:47
2listener:
Т.е. пока без высокоуровневых конструкций, главное чтобы после компилляции код был работоспособен. Вообщем чем проще (низкоуровневей) получится исходник - тем понятнее будет что в нём делать дальше. Но это лишь моё imho.
Да, именно так. Т.е. что бы можно было изменить/добавить/удалить какой-либо сценарий игрового процесса.Если под "скрипт билдером" понимается ide, с возможностью написания своих и редактирования имеющихся скриптов
ИнтересноЯ собираюсь здесь собрать вместе заметки, которые у меня есть на эту тему.
Буду рад, даже если в распакованом виде это будет выглядеть приблизительно так:Начнем с того, что лично я не знаю, как выглядят исходники скриптов IV.
: Имя_секции_плюс_смещение код операции: <код команды><параметры> код операции: <jump> <адрес смещения>ну и файл подстановки, в котором со временем можно будет менять <коды команд> на вразумительные имена.
Т.е. пока без высокоуровневых конструкций, главное чтобы после компилляции код был работоспособен. Вообщем чем проще (низкоуровневей) получится исходник - тем понятнее будет что в нём делать дальше. Но это лишь моё imho.
Сообщение отредактировал Capushon: 13 April 2009 - 15:48
Сначала ты надежда и гордость,
Потом о спину ломают аршин. ©БГ
#6
listener
-
- Главные администраторы
-
- 356 сообщений
Активный участник
- Пол:Мужчина
- Город:Ft.Lauderdale
-
Отправлено 17 April 2009 - 11:39
Я тут выпадал из реальности на недельку, так что подзадержался с ответами и продолжением.
Что касается кодов операций - декомпиляторы для скриптов были готовы еще в прошлом мае. Да, некоторые тонкости выяснились совсем недавно, но, в общих чертах, все было готово.
Опкоды описаны и документированы (в англовики они есть, в каком-то приближении), за исключением работы с protected buffers на PC.
Проблема в том, что писать на этом псевдоассемблере не получится - слишком много нужно считать, что происходит в стеке. Сложность получается примерно такая же, как писать на x86 непосредственно в машинном коде (с ручным рассчетом переходов).
К счастью, все гораздо проще.
Лирическое отступление для людей, не знакомых с теориее компиляции
В теории компиляции (и декомпиляции), помимо представлений в виде исходного текста и машинного кода/байткода, есть промежуточный слой - так называемое абстрактное синтаксическое дерево (Abstract Syntax Tree).
На этом этапе, все конструкции программы представляются в достаточно высокоуровневом виде, но не зависят от того, как все это выглядело в исходном тексте.
Есть присваивание, условный оператор, цикл и т.д., при этом совершенно не важно, как это все было написано. Смысл присваивания не меняется от того, пишем ли мы a = b, a:=b или let a = b
В отсутствие оптимизации (а в IV она не используется), каждой конструкции AST, соответствует однозначаная кодовая последовательность. В итоге, весь кодогенератор (если не учитывать объявления самих классов AST) укладывается примерно в сто строк. Обратное преобразование занимает больше, но там нужно создавать/проверять переменные.
В прошлом посте, я остановился на типах данных. Надо привести несколько примеров, чтобы показать, что с ними можно делать.
Внимание! Это относится к недописанной части.
Я не уверен, что все сделаю в первой версии. Если есть замечания по синтаксису, лучше высказать их сразу.
Что касается кодов операций - декомпиляторы для скриптов были готовы еще в прошлом мае. Да, некоторые тонкости выяснились совсем недавно, но, в общих чертах, все было готово.
Опкоды описаны и документированы (в англовики они есть, в каком-то приближении), за исключением работы с protected buffers на PC.
Проблема в том, что писать на этом псевдоассемблере не получится - слишком много нужно считать, что происходит в стеке. Сложность получается примерно такая же, как писать на x86 непосредственно в машинном коде (с ручным рассчетом переходов).
К счастью, все гораздо проще.
Лирическое отступление для людей, не знакомых с теориее компиляции
В теории компиляции (и декомпиляции), помимо представлений в виде исходного текста и машинного кода/байткода, есть промежуточный слой - так называемое абстрактное синтаксическое дерево (Abstract Syntax Tree).
На этом этапе, все конструкции программы представляются в достаточно высокоуровневом виде, но не зависят от того, как все это выглядело в исходном тексте.
Есть присваивание, условный оператор, цикл и т.д., при этом совершенно не важно, как это все было написано. Смысл присваивания не меняется от того, пишем ли мы a = b, a:=b или let a = b
В отсутствие оптимизации (а в IV она не используется), каждой конструкции AST, соответствует однозначаная кодовая последовательность. В итоге, весь кодогенератор (если не учитывать объявления самих классов AST) укладывается примерно в сто строк. Обратное преобразование занимает больше, но там нужно создавать/проверять переменные.
В прошлом посте, я остановился на типах данных. Надо привести несколько примеров, чтобы показать, что с ними можно делать.
Внимание! Это относится к недописанной части.
Я не уверен, что все сделаю в первой версии. Если есть замечания по синтаксису, лучше высказать их сразу.
// простые переменные
int a; // просто целочисленная переменная
float b; // тоже просто переменная, но с плавающей точкой
int a = 10; // объявляем и присваиваем начальное значение
vector c = { 100.0f, 100.0f, 0.0f }; // объявляем и инициализируем вектор
int m[5] = { 12, 23, 34, 45, 56 }; // массив. пять элементов
// насчет двухмерных массивов - они будут, но я не уверен, что в первой версии
int h = $SAFE_HOUSE; // инициализация переменной хэшем от строки "SAFE_HOUSE"
int h1 = ${SAFE HOUSE}; // аналогично, только строка с пробелом
struct S {
int fa;
int fb;
float fc[4];
};
S str1[2] = {
{ 1, 2, { 0f, 0.1f, 2f, 3.4f }},
{ 5, 0x1000, { 9.81f, 32768.0f, 481.0, 10 }}
};
// со строками у меня пока есть немного непонятные места.
// если есть лучшие предложения - предлагайте.
string[16] s; // переменная-строка. максимальная длина - 16 символов
string[32] sa[4]; // массив из четырех строк по 32 символа
string[] sb = "some text"; // инициализированная переменная. Размер считается автоматически
int& ra = a; // ссылка на переменную a. Если делать ra = 2, в a будет занесено 2.
int& rb = ra; // rb также указывает на a. (Нужно ли что-то добавлять к синтаксису, чтобы избежать ошибок?)
// константы
// в отличие от переменных, по константы не выделяется память. Вместо этого, сразу используется значение
const int d = 1024;
// константы-структуры, скорее всего, будут. Насчет констант массивов - я еще не решил
const vector one = { 1f, 1f, 1f };
vector oneToo = one;
Сообщение отредактировал listener: 17 April 2009 - 17:20
You think your day was surreal? Try mine.
#7
Chipsman
-

- Главные администраторы
-
- 786 сообщений
Активный участник
- Пол:Не определился
-
")
Отправлено 17 April 2009 - 17:05
ну для меня вроди-бы все понятно,
ну по идее проблем не должно возникать, ну а какие еще например могут быть варианты получше?int& ra = a; // ссылка на переменную a. Если делать ra = 2, в a будет занесено 2. int& rb = ra; // rb также указывает на a. (Нужно ли что-то добавлять к синтаксису, чтобы избежать ошибок?)
#8
CatZilla
-

- LCSTeam
-
- 35 сообщений
Активный участник
- Пол:Мужчина
Отправлено 17 April 2009 - 18:03
Отличный синтаксис аля с, с++. Будет приятно скриптить.

#9
Capushon
-
- Пользователи
-
- 39 сообщений
Активный участник
- Пол:Мужчина
- Город:Украина
Отправлено 18 April 2009 - 21:54
2listener:

А почему "замечания по синтаксису, лучше высказать их сразу" ? Потом что-то менять в этом плане уже будет нельзя?
2АДМИНЫ:
Почините пожалуйста тэг _CODE_, текст выглядит в нём просто отвратительно и нечитабельно !!!!! ...
Вот так:
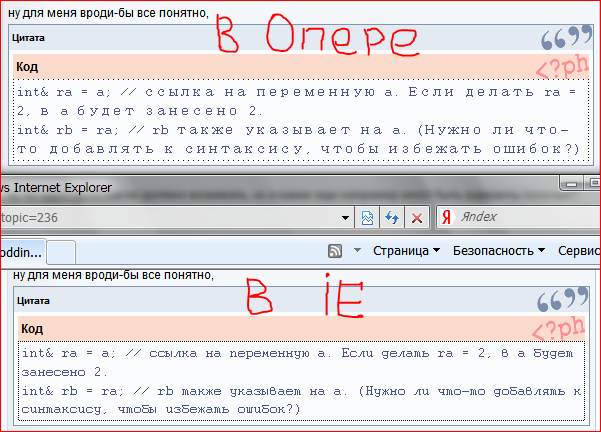
А хотелось бы вот так:
(как на http://sannybuilder.com/forums/)
Это отлично.Что касается кодов операций - декомпиляторы для скриптов были готовы еще в прошлом мае. Да, некоторые тонкости выяснились совсем недавно, но, в общих чертах, все было готово.
А когда можно будет увидеть первую версию?Внимание! Это относится к недописанной части.
Я не уверен, что все сделаю в первой версии.
Синтаксис, как синтаксис - к любому можно привыкнуть, хотелось бы конечно OPR-коды в началах строк видеть, привык, но если это не возможно - привыкнем к новому виду кода.Если есть замечания по синтаксису, лучше высказать их сразу.
А почему "замечания по синтаксису, лучше высказать их сразу" ? Потом что-то менять в этом плане уже будет нельзя?
2АДМИНЫ:
Почините пожалуйста тэг _CODE_, текст выглядит в нём просто отвратительно и нечитабельно !!!!! ...
Вот так:
А хотелось бы вот так:
(как на http://sannybuilder.com/forums/)
Сначала ты надежда и гордость,
Потом о спину ломают аршин. ©БГ
#10
listener
-
- Главные администраторы
-
- 356 сообщений
Активный участник
- Пол:Мужчина
- Город:Ft.Lauderdale
-
Отправлено 19 April 2009 - 08:25
Насчет первой версии, я боюсь называть сроки - как правило, назвать дату - гарантированный способ не сделать к этой дате ничего.
Сейчас не хватает двух частей: самого парсера и работы с переменными.
Написать этот пример было очень полезно - многое прояснилось и многое оказалось проще, чем я думал в начале.
Что касается опкодов в начале - для стековой машины это очень неудобно: простейшие с вида конструкции могут разворачиваться в дикое количество кода (в том же OpenIV есть просмотр как высокого уровня, так и ассемблера - можно сравнить).
Если вспоминать случаи с кодогенерацией, у меня в практике был случай, когда компилятор для HC908 (он не совсем стековый, но регистров у этого контроллера всего два) развернул две строки текста в 390 байт (и 8К встроенного флеша не хватило).
Насчет замечаний по синтаксису - я очень не люблю работать над задачей, когда техзадание постоянно меняется (и покажите мн того, кто это любит). Сейчас, пока парсер только проектируется, самое время учесть все замечания.
You think your day was surreal? Try mine.
#11
Capushon
-
- Пользователи
-
- 39 сообщений
Активный участник
- Пол:Мужчина
- Город:Украина
Отправлено 20 April 2009 - 21:43
2listener:

ps: А почему все переехали на этот форум? http://sannybuilder.com/forums/ мне больше нравился, да и по теме он более подходит.
Насчет первой версии, я боюсь называть сроки - как правило, назвать дату - гарантированный способ не сделать к этой дате ничего.
Хорошо бы посмотреть на синтаксис реального треда из игры, как это будет выглядеть, тогда возможно появятся замечания.Сейчас, пока парсер только проектируется, самое время учесть все замечания.
ps: А почему все переехали на этот форум? http://sannybuilder.com/forums/ мне больше нравился, да и по теме он более подходит.
Сначала ты надежда и гордость,
Потом о спину ломают аршин. ©БГ
#12
Capushon
-
- Пользователи
-
- 39 сообщений
Активный участник
- Пол:Мужчина
- Город:Украина
Отправлено 12 May 2009 - 00:05
2listener:
Давно никаких вестей небыло...
Что там нового по разработке?
Давно никаких вестей небыло...
Что там нового по разработке?
Сначала ты надежда и гордость,
Потом о спину ломают аршин. ©БГ
#13
Chipsman
-
- Главные администраторы
-
- 786 сообщений
Активный участник
- Пол:Не определился
-
Отправлено 12 May 2009 - 16:20
дейсвительно, давно ничего не слышно..
#14
listener
-
- Главные администраторы
-
- 356 сообщений
Активный участник
- Пол:Мужчина
- Город:Ft.Lauderdale
-
Отправлено 13 May 2009 - 05:46
Как обычно по весне: работа, простуда, сезонный депресняк....
Если все будет нормально (с первым со вторым и с третьим), сегодня-завтра будет продолжение.
(либо что-то низкоуровневое про опкоды, либо выражения и операторы)
You think your day was surreal? Try mine.
#15
Capushon
-
- Пользователи
-
- 39 сообщений
Активный участник
- Пол:Мужчина
- Город:Украина
Отправлено 13 May 2009 - 14:12
2listener:
Ок! Ждём возвращения из депреснякаЕсли все будет нормально (с первым со вторым и с третьим), сегодня-завтра будет продолжение.
Сначала ты надежда и гордость,
Потом о спину ломают аршин. ©БГ
#16
VcSaJen
-

- Пользователи
-
- 270 сообщений
Активный участник
- Пол:Мужчина
- Интересы:GTA, скриптинг в GTA.
-
Отправлено 15 May 2009 - 23:34
Насчёт ситаксиса:
можно сделать так, чтобы разделитель поля структуры и структуры был не Struct->Field, а был Struct.Field? Сочетание символов -> слишком неудобное.
Вопрос: Будет ли нормальная арифметика типа "X=(X1+X2)/2" и "D=sqrt(X*X+Y*Y)" ?
#17
Capushon
-
- Пользователи
-
- 39 сообщений
Активный участник
- Пол:Мужчина
- Город:Украина
Отправлено 15 May 2009 - 23:43
2VcSaJen:
Да - это хорошая идея!нормальная арифметика типа "X=(X1+X2)/2" и "D=sqrt(X*X+Y*Y)"
Сначала ты надежда и гордость,
Потом о спину ломают аршин. ©БГ
#18
listener
-
- Главные администраторы
-
- 356 сообщений
Активный участник
- Пол:Мужчина
- Город:Ft.Lauderdale
-
Отправлено 20 May 2009 - 10:06
Касательно синтаксиса: выражения будут поддерживаться любой сложности (иначе просто не получится). Для структур будет использоваться точка (поскольку указателей не будет).
Эти два вопроса были очень кстати. Пока у меня завал по работе и большого прогресса нет, я все равно собирался рассказать немного о виртуальной машине. Не претендуя на полноту и хоть какую-то структурированность, я хотел рассказать немного о командах, как они работают, и почему нельзя воспользоваться тем подходом, который использовался в SA и раньше. Необходимое замечание: поскольку сейчас общепринятого стандарта на именование опкодов нет, более того, я сам до конца не уверен в корректности названия пары команд, запись parray (65) означает команду parray с кодом 65 (десятичное).
Итак, в IV используется стековая машина. Это означает, что команды получают большинство операндов со стека. На стек же кладутся все результаты. Стек - обычный, LIFO. Обращение возможно только к вершине стека. (Формально, можно добраться до произвольного элемента через pstatic или pframe. На практике, такое выходит за границы разумного).
Команды можно поделить на несколько больших категорий. (Это деление весьма условно, моя классификация основана на удобстве использования в декомпиляторе).
1. push - поместить значение на стек. К этой группе относятся команды, которые берут immediate аргумент и помещают его на стек. Таких команд три (по количеству простых типов): ipush, fpush (42) и spush (67). Для уменьшения размера кода, ipush существует в нескольких вариантах: пятибайтовый ipush (41), трехбайтовый ipush2 (40) и однобайтовый ipush1 (80..111). В качестве аргумента, ipush и ipush2 используют, соответственно, 32-битовый и 16-битовый signed int. При помещении на стек, операнд расширяется до 32 бит (со знаком). Аргумент ipush1 берется из кода команды (opcode - 0x60). Теоретически, можно использовать и коды в диапазоне 112..255, но нет никакой гарантии, что в одной из следующих версий, они не будут использованы для чего-то другого. Аргумент fpush - обычный float (32бит) Аргумент spush - строка длиной до 255 байт, перед которой идет байт длины. На стек заносится указатель на строку (не на длину!) Длина строки и какой вариант ipush использовать - целиком и полностью в ведении кодогенератора.
2. унарные операторы. Унарный оператор берет один аргумент со стека и помещает результат на стек. К унарным операторам у меня относится команды: ineg (7), fneg (19), vneg (30), inot (6) и команды преобразования типов itof (37), ftoi (38), ftov (39). *neg - меняют знак операнда (для вектора - меняется знак всех трех компонентов). inot - логическая инверсия (возвращается 1, если аргумент нулевой и 0, если ненулевой). itof и ftoi должны быть очевидны. ftov берет в качестве аргумента float и возвращает вектор, все элементы которого равны значению этого float.
3. Бинарные операторы Все точно также, только аргументов со стека берется два. Первый аргумент помещается на стек первым, второй, как ни странно, вторым. Двадцать девять команд для арифметических действий и сравнения.
4. Указатели. Несмотря на то, что на высоком уровне использовать указатели нельзя, на уровне команд они весьма активно используются. Команда для помещения указателя берет со стека смещение в сегменте (в DWORD-ах) и помещает в стек указатель на требуемую переменную. К таким командам относятся: pglobal (64), pstatic (63) и pframe (62). У pframe есть короткая форма, в которой смещение берется из кода команды pframe0 .. pframe7 (54..61). К этой же группе, у меня относится команда с кодом 68, которая помещает в стек указатель на неизвествую структуру виртуальной машины.
5. Операции над стеком. pnset (52) и pnget (53) берут со стека два аргумента: размер структуры и указатель на нее. Структура, соответственно команде, копируется либо со стека в переменную, либо из переменной в стек. Размер указывается в DWORD-ах. pset (50) и pget (49) - более часто встречающаяся форма, используемая для простых типов. Один аргумент - указатель, размер равен 1 (4 байта). parray (65) - поместить на стек указатель на элемент массива. Три аргумента: указатель, размер элемента массива в DWORD-ах и индекс в массиве. При вычислении указателя производится проверка на переполнение. Поскольку, для проверки на переполнение, в массиве имеется поле с количеством элементов, его нужно инициализировать. Для этого используется команда с кодом 51. Раньше она называлась ppeekset. В свете того, что она используется только для инициализации массивов, скорее всего она будет переименована в arraydef или что-то аналогичное. У нее два аргумента: указатель и значение. После выполнения, указател остается на стеке (внимание! в отличие от pset, указатель идет первым, а значение - вторым). Следующие две команды должны быть хорошо знакомы любому, кто писал на forth. Это dup (43) и drop (44). Они также используются при инициализации массива. Кроме этого, drop используется, если требуется проигнорировать результат выражения (например, вызова функции). В отличие от регистровой модели, любой результат должен быть либо использован, либо выброшен.
6. Операции со строками. sadd (71) - слияние строк. Первым параметром передается указатель на добавляемую строку, вторым - указатель на строку, к которой будет добавлено. immediate аргумент команды - размер буфера строки-результата. saddi (72) - полностью аналогична sadd, но в качестве добавляемого параметра берется int, преобразуется в строку и дописывается к результату. itos (73) - аналогична saddi, только число просто конвертируется в стрку, а не добавляется к результату. sncpy (75) - копирование строки с проверкой длины буфера. Три аргумента, immediate-размера нет. Поведение команды полностью аналогично функции strncpy_s
7. Команды передачи управления j (34) - безусловный переход. Адрес (4 байта) - immediate агрумент команды. jf (35) - условный переход, со стека берется значение; переход выполняется, если оно равно нулю. switch (66) native (45) - вызов функции из exe call (46) - вызов функции скрипта enter (47) - создание стекового фрейма функции, первая команда любой функции ret (48) - завершить функцию, освободить стековый фрейм и вернуть результат 8. Работа с live protected buffers Три команды с кодами 76, 77, 78. У меня пока не разобраны. Используются только в PC-версии
You think your day was surreal? Try mine.
#19
listener
-
- Главные администраторы
-
- 356 сообщений
Активный участник
- Пол:Мужчина
- Город:Ft.Lauderdale
-
Отправлено 28 May 2009 - 12:10
Тем временем...
Выше, я говорил про большое количество дублирующегося кода.
Вчера сделал сигнатурный анализатор. Из 50499 функций, уникальных всего 9107.
Листинг дизассемблера уменьшился с 5.5М строк, до 2.1М (93Мб => 36Мб)
You think your day was surreal? Try mine.
#20
JNikc
-

- Пользователи
-
- 36 сообщений
Активный участник
- Пол:Мужчина
- Город:SPB
Отправлено 28 May 2009 - 14:52
Очень интересная тема. Но я хочу задать вопрос который уже задавал на sannybuilder.com и listener дал мне это обсуждение. Речь идет о степени абстрактности скриптового языка. Согласить язык для игр и язык общего назаначения это разные вещи - первый должен быть удобен, а второй предоставлять большую мощь. Т.е. нет необходимости делать синтаксис КАК Си или КАК паскаль.
К примеру есть у нас игра Х (GTA SA, GTA 4, и что угодно лишь бы скриптинг поддерживала). Я вижу необходимость в следующих предустоновленных классах:
Player - игрок в иговом мире
Around - его окружение
Gamer - игрок у компьютера
GameExe - игра как программа
и т.д.
Тогда всё что угодно можно стделать получив метод этих классов. К примеру любая игра в которой у игрока есть здоровье должна поддерживать
Player.Health = ...
Или
Around.ClousePed
чтобы получить ближаешего педа. Ну и так далее.
Загрузка и выгрузка моделей - этим скриптер заниматься не должен, это должно быть зашито в методах. При таком подходе использование условий циклов и переменных ограничивается, большую часть мы можем реализовать в методах.
Короче! Такой язык универсален для любой игры, т.е. один и тот же код работает для разных игр (или хотя бы для линейка ХТА) так как все они похожи. Но в зависимости от игры он преобразуется в РАЗНЫЙ низкоуровневый код.
Я понимаю что щас витаю в геймерских облаках. Люди тут титанически занимаются разработкой снизу вверх, а я лезу с этим. Но у меня есть опыт (небольшой :-) в синтаксических интерпретаторах. Но нет никакого представления о том как устроен байт-код ГТА. Тем не менее может кому-то интересно. Меня бы прикололо если вместо ста строк скрипта я бы мог забить пять и достичь того же эффекта!









Количество пользователей, читающих эту тему: 0
0 пользователей, 0 гостей, 0 анонимных

